Qu’est-ce qu’un modèle de langage (LLM) ?
Un LLM (Large Language Model) est un programme informatique entraîné sur des milliards de textes pour comprendre et générer du langage humain. ChatGPT, Claude, Gemini, Llama et Mistral sont tous des LLM. Quand vous posez une question à ChatGPT et qu’il vous répond avec une phrase cohérente, c’est un LLM en action.
Pour simplifier : un LLM est un système de prédiction de mots extrêmement sophistiqué. Il analyse votre texte d’entrée et prédit, mot par mot, la suite la plus probable et la plus pertinente. Cette capacité de prédiction, entraînée sur des quantités massives de texte (livres, articles, sites web, conversations), produit des résultats qui ressemblent à une compréhension réelle du langage.
Comment un LLM est-il entraîné ? Les 3 étapes clés
Étape 1 : Le pré-entraînement (pre-training) — Le modèle ingère des centaines de milliards de mots provenant d’internet, de livres, d’articles scientifiques et de code source. Il apprend les structures du langage, la grammaire, les faits, le raisonnement et même les nuances culturelles. GPT-4 a été entraîné sur environ 13 000 milliards de tokens (mots et sous-mots). Cette phase nécessite des milliers de GPU pendant des semaines et coûte entre 10 et 100 millions de dollars. C’est pourquoi seules les grandes entreprises (OpenAI, Google, Meta, Anthropic, Mistral) peuvent créer des LLM de pointe.
Étape 2 : Le fine-tuning (ajustement fin) — Le modèle pré-entraîné est ensuite affiné sur des exemples de conversations de qualité. Des annotateurs humains créent des milliers de paires question-réponse qui montrent au modèle comment répondre de manière utile, précise et sûre. Cette étape transforme un modèle qui prédit du texte en un assistant capable de suivre des instructions.
Étape 3 : L’alignement avec RLHF — RLHF (Reinforcement Learning from Human Feedback) est la technique qui rend les LLM agréables à utiliser. Des évaluateurs humains comparent plusieurs réponses du modèle et classent la meilleure. Le modèle apprend à produire des réponses que les humains préfèrent : plus claires, plus honnêtes et moins dangereuses. C’est cette étape qui différencie un modèle brut (qui peut produire du contenu toxique) d’un assistant poli et utile.
L’architecture Transformer : le moteur des LLM
Tous les LLM modernes sont basés sur l’architecture Transformer, inventée par des chercheurs de Google en 2017 dans l’article « Attention Is All You Need ». L’innovation clé est le mécanisme d’attention (attention mechanism) qui permet au modèle de regarder simultanément tous les mots d’un texte pour comprendre les relations entre eux.
Prenons un exemple concret. Dans la phrase « Le chat qui dormait sur le canapé du salon a renversé le vase », le mécanisme d’attention permet au modèle de comprendre que « a renversé » se rapporte à « chat » et non à « canapé » ou « salon », même si ces mots sont plus proches dans la phrase. Les anciens modèles (RNN, LSTM) traitaient les mots séquentiellement et perdaient cette connexion sur les phrases longues.
Les LLM se déclinent en trois familles. Les modèles autorégressifs (GPT, Llama, Mistral) génèrent du texte mot par mot de gauche à droite — c’est le type utilisé par ChatGPT. Les modèles encodeurs (BERT) analysent un texte dans les deux sens pour le comprendre — utilisés pour la classification, la recherche sémantique et l’analyse de sentiments. Les modèles encodeur-décodeur (T5, BART) combinent compréhension et génération — utilisés pour la traduction et le résumé.
Comparatif des principaux LLM en 2026
GPT-4o (OpenAI) — Le modèle le plus utilisé via ChatGPT. Multimodal (texte, images, audio, vidéo). Fenêtre de contexte de 128 000 tokens. Excellent en raisonnement, rédaction et code. Accès via ChatGPT Plus (20$/mois) ou API (0,005$/1K tokens en entrée). Forces : polyvalence, qualité de rédaction. Faiblesses : coût API élevé pour les gros volumes, modèle propriétaire fermé.
Claude 3.5 Sonnet (Anthropic) — Concurrent direct de GPT-4o. Fenêtre de contexte de 200 000 tokens (la plus grande). Excelle en analyse de documents longs, rédaction nuancée et code. Accès via claude.ai (gratuit limité ou 20$/mois) ou API. Forces : contexte très long, réponses nuancées, moins d’hallucinations. Faiblesses : pas de génération d’images native.
Gemini 1.5 Pro (Google) — Modèle multimodal avec une fenêtre de contexte d’un million de tokens. Intégré à Google Workspace, Search et Android. Forces : intégration Google, contexte massif. Faiblesses : qualité parfois inférieure à GPT-4o et Claude sur les tâches complexes.
Llama 3 (Meta) — Le meilleur modèle open source. Disponible en versions 8B, 70B et 405B paramètres. Téléchargeable gratuitement et exécutable en local. Forces : gratuit, open source, personnalisable, données restent privées. Faiblesses : nécessite du matériel puissant pour les grosses versions, pas d’interface grand public native.
Mistral (Mistral AI, France) — Startup française qui produit des modèles compétitifs et efficaces. Mistral Large rivalise avec GPT-4. Mistral 7B et Mixtral 8x7B sont open source et fonctionnent sur du matériel modeste. Forces : excellent rapport qualité/taille, open source, entreprise européenne (conforme RGPD). Idéal pour les déploiements en entreprise soucieuses de la souveraineté des données.
Les concepts clés pour comprendre les LLM
Tokens — Les LLM ne traitent pas des mots mais des tokens, qui sont des fragments de mots. « Sénégal » peut être découpé en « Sén » + « ég » + « al » (3 tokens). En français, un mot fait environ 1,5 token en moyenne. Le prix des API est calculé par token. La fenêtre de contexte (context window) est le nombre maximum de tokens que le modèle peut traiter en une seule conversation — tout ce qui dépasse est « oublié ».
Température — Un paramètre qui contrôle la créativité du modèle. Température 0 : le modèle choisit toujours le mot le plus probable (réponses déterministes, factuelles). Température 1 : le modèle explore des mots moins probables (réponses créatives, variées). Pour des tâches factuelles (analyse de données, extraction d’informations), utilisez une température basse (0-0,3). Pour la rédaction créative, utilisez une température plus élevée (0,7-1).
Hallucinations — Les LLM inventent parfois des informations qui semblent vraies mais sont fausses. Un LLM peut citer un article scientifique qui n’existe pas, ou donner une date erronée avec assurance. C’est la limitation la plus importante à comprendre. Pour réduire les hallucinations : demandez au modèle de citer ses sources, utilisez le RAG (Retrieval-Augmented Generation) pour connecter le LLM à des données vérifiées, et vérifiez toujours les faits critiques.
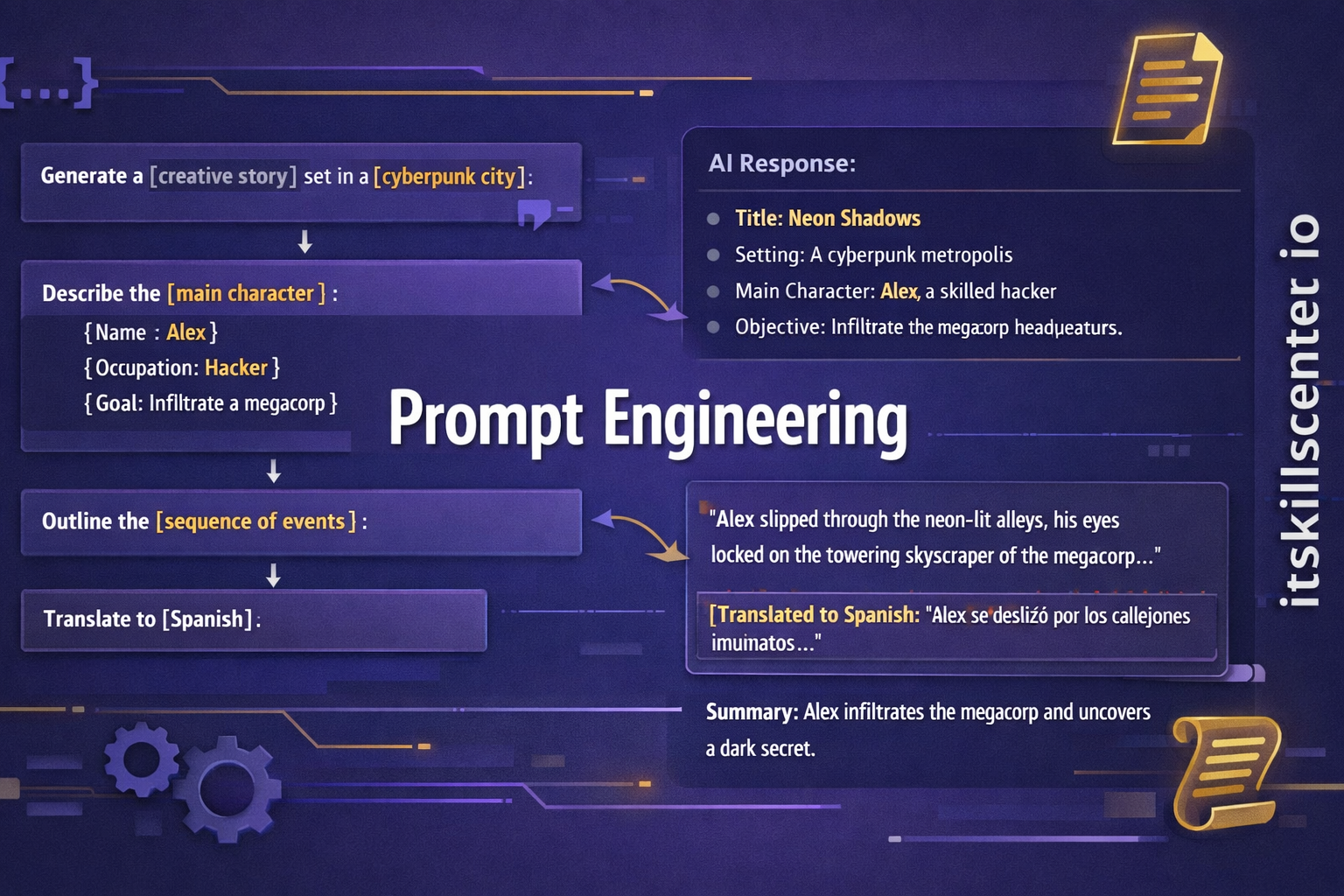
Prompt engineering — L’art de formuler vos instructions pour obtenir les meilleurs résultats du LLM. Un prompt précis, structuré et contextualisé produit des résultats radicalement meilleurs qu’une question vague. Techniques essentielles : role prompting (définir un rôle expert), few-shot (donner des exemples), chain-of-thought (demander un raisonnement étape par étape).
Utiliser les LLM en local : Ollama et les modèles open source
Vous pouvez exécuter des LLM directement sur votre ordinateur sans envoyer vos données à un serveur externe. Ollama (ollama.com) est l’outil le plus simple pour installer et exécuter des modèles open source en local. Installation en une commande, interface en ligne de commande ou via API locale.
Modèles recommandés pour Ollama selon votre matériel : avec 8 Go de RAM, utilisez Mistral 7B ou Llama 3 8B (réponses de bonne qualité pour les tâches courantes). Avec 16 Go de RAM, utilisez Llama 3 70B en quantification Q4 (qualité proche de GPT-3.5). Avec un GPU NVIDIA de 24 Go VRAM, utilisez Mixtral 8x7B ou Llama 3 70B (qualité proche de GPT-4 pour de nombreuses tâches).
L’avantage majeur des LLM en local pour les entreprises sénégalaises : vos données ne quittent jamais votre machine. Pour un cabinet comptable, un cabinet d’avocats ou un établissement de santé qui traite des données sensibles, c’est un argument décisif par rapport aux API cloud.
Les limites actuelles des LLM à connaître
Pas de raisonnement réel — Les LLM simulent le raisonnement en reproduisant des patterns vus pendant l’entraînement. Ils peuvent résoudre des problèmes mathématiques courants mais échouent souvent sur des problèmes de logique inhabituels. Ne leur confiez pas de décisions critiques sans vérification humaine.
Connaissances figées — Un LLM ne connaît que ce qui existait avant sa date de coupure d’entraînement. Il ne sait pas ce qui s’est passé hier. Le RAG et la recherche web (comme Perplexity AI ou ChatGPT avec navigation) contournent partiellement cette limitation.
Biais et représentativité — Les LLM reflètent les biais présents dans leurs données d’entraînement, majoritairement en anglais et issues de sources occidentales. Les contextes africains, les langues locales (wolof, bambara, haoussa) et les réalités du continent sont sous-représentés. Gardez cet angle critique quand vous utilisez un LLM pour des sujets liés à l’Afrique.
Coût et consommation énergétique — L’entraînement et l’utilisation des LLM consomment énormément d’énergie. Une requête GPT-4 consomme environ 10 fois plus d’énergie qu’une recherche Google classique. Ce coût environnemental pousse la recherche vers des modèles plus petits et plus efficaces (comme Mistral 7B qui atteint des performances remarquables avec une fraction des ressources).